



Is Fortran Memory Safe?
Fofrtran’s allocatable arrays cannot leak memory, or leave dangling pointers, but how well do current Fortran compilers enforce memory safety? Check out our updated compiler comparison chart.
plusFORT Version 8 – Gets rid of ALL GOTOs
Version 8 is our biggest ever update, and it’s free for personal, educational and academic users working on non-commercial projects.
- SPAG uses structure templates to unscramble spaghetti code. In earlier versions, there were three major templates:-
-
- Block IF statements
- DO loops with EXIT and CYCLE
- Single statement code replication
Version 8 adds two new templates which allow it to remove all GOTOs in even the most convoluted code. These are:
-
- Dispatch loops. SPAG identifies separately addressable code blocks (block 1, block 2 etc.), and relocates them into a SELECT CASE construct for execution in the correct sequence, under control of a dispatch loop.
- Internal Subroutines. SPAG identifies separately addressable code blocks, and relocates them into internal
subroutines. Blocks are invoked in the correct order using CALL statements, and the calls may be recursive.
These two new templates provide alternative ways to express the same control flow. SPAG allows you to select either one, but the default is to use internal subroutines in simpler cases, where there is no recursion, and dispatch loops otherwise. In practice, internal subroutines are a natural way to express many simple cases, for example where a code fragment is used to tidy up before exiting a subprogram. Conversely, dispatch loops keep a strict cap on the complexity of more complex codes.
Examples may be found in section 2.7.1 of the plusFORT manual.
- Version 8 benefits from a major internal upgrade which removes a long-standing limitation to SPAG’s symbolic analysis, allowing it to “look ahead”, and reliably identify the characteristics of subprograms with and without explicit interfaces. This change has knock-on effects throughout SPAG and GXCHK, for example in improved reporting and error detection. It also enables new functionality both in this release and in the future.
- SPAG’s prescan, which allows it re-order input files so that MODULES are processed before code that uses them without the use of makefiles or external props, has been extended and improved.
- SPAG now uses the standard ISO_FORTRAN_ENV module to allow it to translate legacy non-standard types, such as INTEGER*1 and REAL*8, to standard Fortran. This supersedes and improves upon the previous treatment using the proprietary F77KINDS module.
- By default, SPAG now inserts a PROGRAM statement at the beginning of code with no subprogram statement, and adds an invented name to un-named BLOCK DATA subprograms.
- SPAG switches to “module-maker” mode when an INCLUDE file (no subprogram or END statement) is encountered.
- Numerous bug fixes.
- Manual updated to revision P.
Free Academic & Trial Licences
A major update to plusFORT – version 8 – will be released in the first week of December 2023. With this release, we also plan some changes to our pricing and licensing:
- With immediate effect, we are scrapping all licence fees for personal, educational and academic users. Eligible users can download a fully functional, unrestricted version of plusFORT for non-commercial, non-government use. These licences may not be used to produce proprietary or closed source code or reports.
- Commercial licence fees will be increased significantly, but not until January 2024. This provides an opportunity for users in business and government agencies to buy the new version at old prices. You may also buy maintenance (for multiple years in advance if required). To take advantage, please be sure to send your PO, or visit our online shop, and complete your purchase before the end of the year.
- Fully functional commercial trial licences are now available on demand.
plusFORT Version 7.60 – Fortran 2003 and More
- Initial support for Fortran 2003. SPAG now supports input and output of Fortran 2003 syntax, including the object oriented programming features. There are some known limitations (documented in the READ.ME file).
- Revised code indentation scheme for free format source form
output. Outdenting for suprogram, CONTAINS and END statements, and optional indentating for executable code relative to declarations. - SPAG can now distinguish automatically between the traditional fixed form (72 characters, sequence numbers in columns 73-80), from the VAX source form (with TABs and longer records).
- The default values for several SPAG configuration options have been changed.
- Various bug fixes and minor cosmetic improvements to restructured code.
- Manual updated to revision M.
plusFORT Version 7.50 – A Major Update
- HyperKWIC can now be run directly from the PFFE graphical user interface.

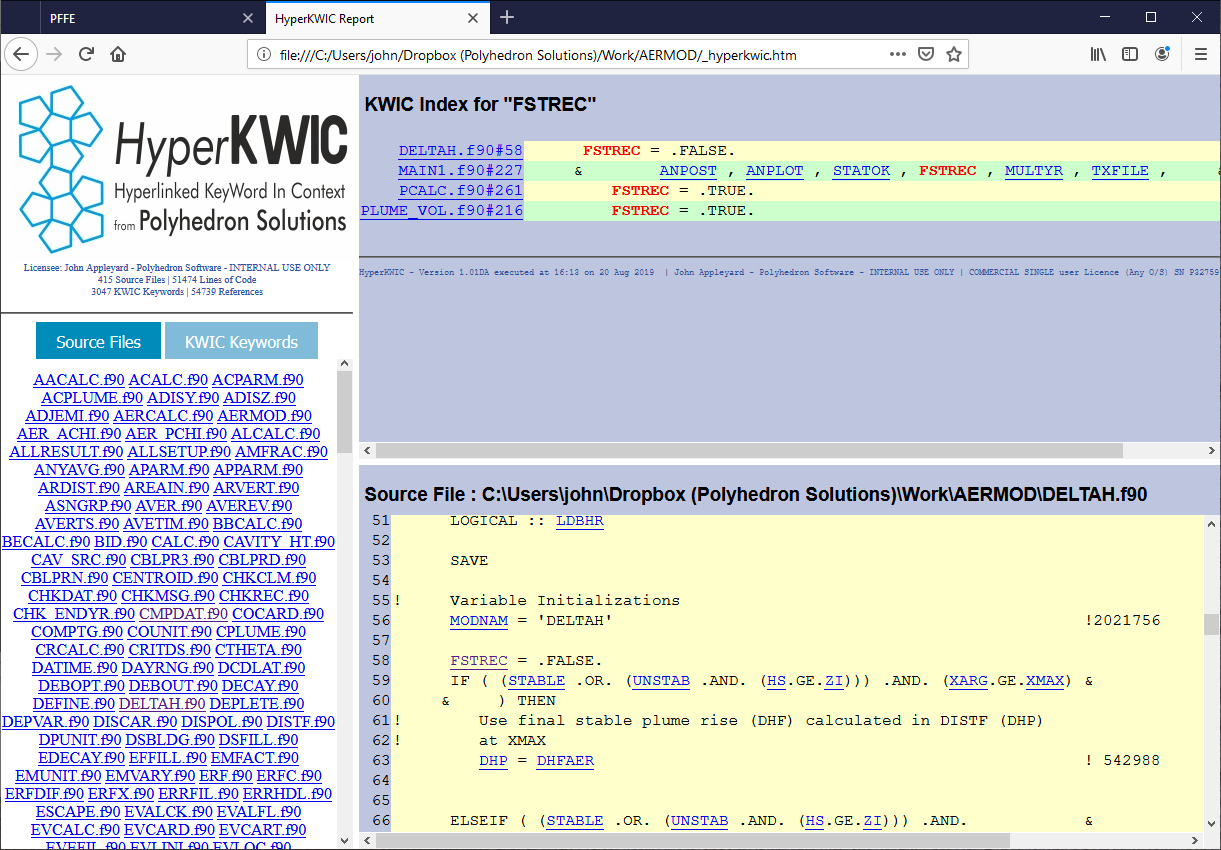
- SPAG now re-orders input files to ensure that MODULES are processed before code that uses them. This ensures that SPAG has the information it needs to make a full and accurate analysis, and is most effective if all the source code of a program is analysed in a single run.
- Improved formatting of declarations rewritten with Fortran 95 syntax
- SPAG writes dummy arguments in the order they appear in the argument list, rather than alphabetically. Each dummy argument is declared in a separate statement to allow end of line comments for each argument.
- SPAG inserts INTENT and OPTIONAL clauses within dummy argument declarations, rather than as separate statements.
- GXCHK produces a new “Internalisation Report”, to help re-engineer legacy Fortran. It shows which subroutines and functions can be converted to internal subprograms, thus reducing the number of separate program units to be combined at link time.

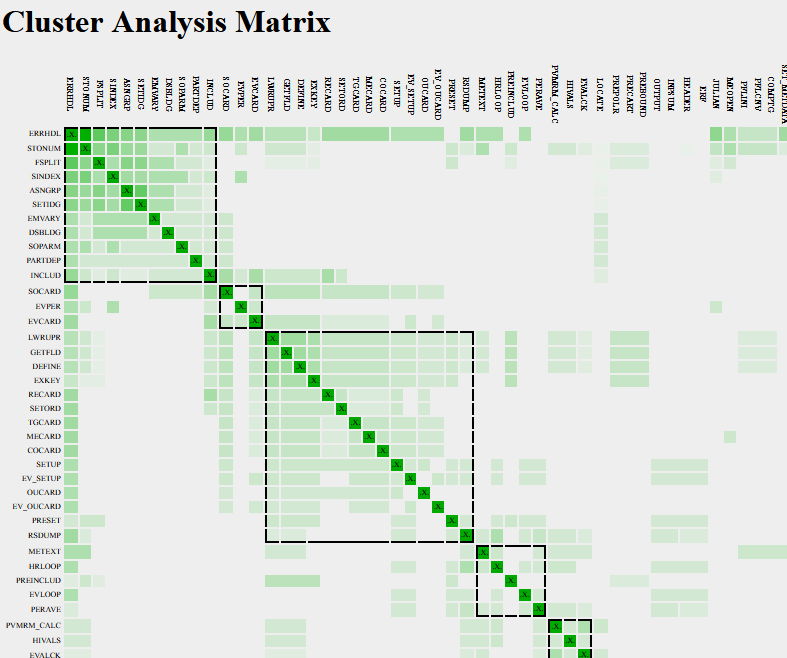
- GXCHK produces a new “Cluster Analysis Matrix” report which identifies groups of subprograms which may, on the basis of data usage and calling patterns, to be candidates for inclusion in modules.
- The name of the HTML report porduced by GXCHK has been changed from gxchk.htm to _gxchk.htm for consistency with other plusFORT tools, and to make it easier to find.
- The default initial working directory for PFFE and the plusFORT Command Prompt have been set to the current user’s Documents directory.
- Possible errors when rewriting declarations from scratch in an internal subprogram fixed.
- The ability to switch off header comments by setting item 220 of SPAG configuration to blanks restored.
- Many other minor fixes and enhancements.
- Manual updated to revision L.
plusFORT Version 7.25 – 64 bit Support
Version 7.25 is the first fully 64 bit version of plusFORT, and in consequence, only 64 bit versions of Windows, Linux and MacOS are supported. In addition, PFFE, the plusFORT graphical user interface has been substantially upgraded, and now supports context sensitive help for all configuration options. Other fixes and enhancements are listed below.
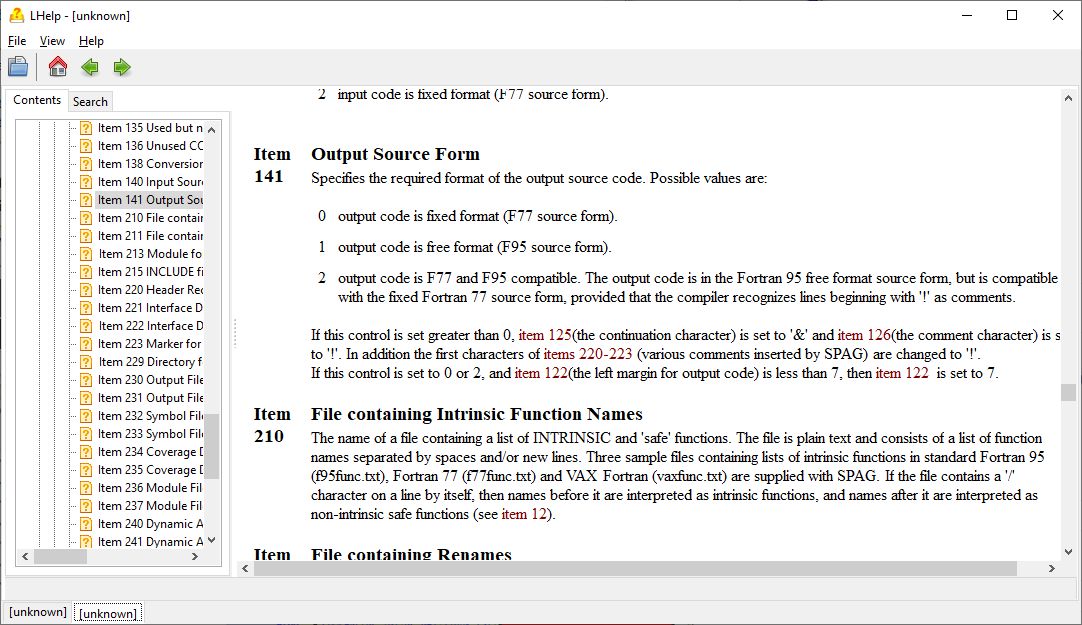
- Full context sensitive help (using F1) in Windows and Linux versions of PFFE.
- PFFE updated to deal gracefully with “starter pack” version.
- Possible broken links in GXCHK hypertext reports fixed.
- Substantial reorganization and re-design of PFFE forms and dialogs.
- Fixed SPAG could put output files in wrong directory when input path contained spaces.
- Fixed misleading message when plusFORT.fig not found.
- Fixed bugs in cvranal and probes.f90 coverage analysis routines relating to paths with spaces.
- Fixed bug in naming of MODULEs created to replace INCLUDE files with names (excluding path and extension) longer than 20 characters.
- Fixed bugs in command line processing on Linux and Mac.
- Big increase in command line buffer on Linux and Mac.
- Numerous improvements in processing long paths with embedded spaces.
- Fixed comments in source code between modules were sometimes lost.
- Various minor fixes and enhancements.
Example of Context Sensitive Help
New – plusFORT Version 7.20
Another big update which introduces a completely new tool to the plusFORT suite.
HyperKWIC is a tool for generating software documentation that combines the instant connectivity of hypertext with the analytical strengths of KeyWord In Context. It produces HTML documents that provide a fully interactive alternative to traditional documentation. HyperKWIC may be used to document source code written in Fortran, C, C++, Delphi or any other mainstream language.
You can interact with sample HyperKWIC reports for large Fortran and C programs by clicking here and here. HyperKWIC reports can be viewed on any system with a reasonably capable web browser, including tablets and smart-phones.
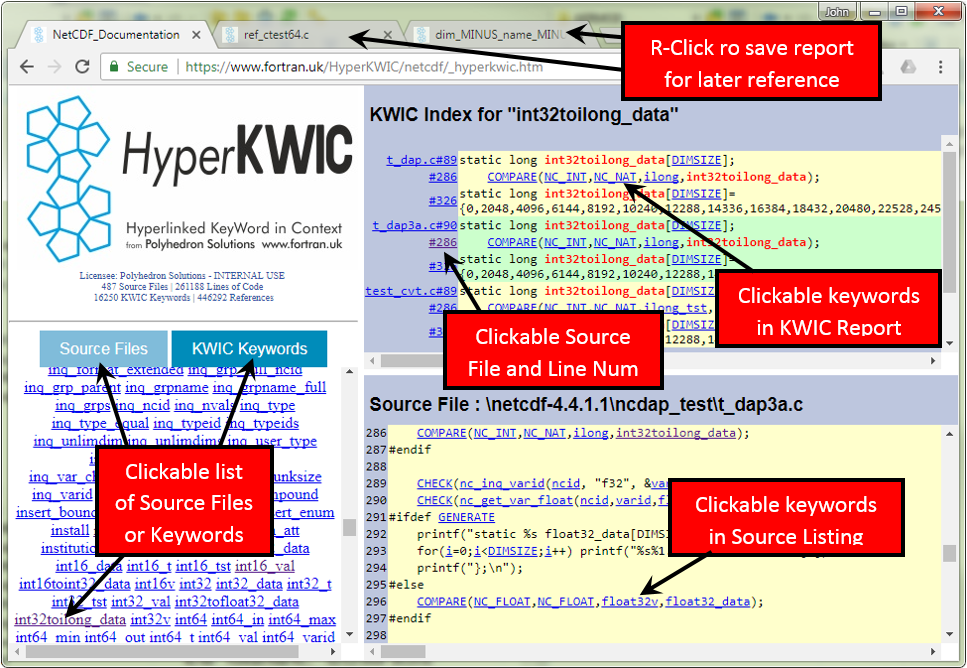
In addition Version 7.20 brings numerous bug fixes and enhancements including the following:-
- Bugs in SPAG processing of WHERE and FORALL constructs and statements fixed.
- Regression in SPAG treatment of a complex inheritance scenario fixed.
- Improved error reporting in SPAG for some non-standard code.
- Improved SPAG treatment of C pre-processor code, including multi-line directives.
- It’s no longer possible for SPAG to write fixed form output with a left margin before column 7.
- SPAG no longer makes multiple copies of comments on lines with multiple statements.
- SPAG produces a message when code beyond the right margin is truncated and the default right margin for free-source form code is increased to 512.
- Improved error reporting when attempting to convert COMMON blocks to MODULEs.
- Manual updated to revision K.
Video Tutorials
Check out our new video tutorials which explore some of the many capabilities of plusFORT, and showcase PFFE, the plusFORT front end which offers a genuinely intuitive graphical interface for the plusFORT tools.
DON’T forget to turn your sound on! We recommend switching to full screen view if you want to follow the details.
Now Here! – plusFORT Version 7.10
A major update with many improvements affecting usability and compatibility of plusFORT.
- PFFE (the plusFORT graphical interface) is now available for Linux and Mac.
- PFFE stability and usability enhancements
- New default behaviour for SPAG output files (restructured output, symbol files, coverage files, and module files). Instead of being
written to the source directory, SPAG creates a subdirectory called SPAGged (or as specified in option 229 of spag.fig) and writes them there. Restructured output files have the extension .f90 (or .for if item 141 is set to 0) instead of .spg. If option 229 is set,
items 230, 231, 232, 234 and 236 are over-ridden. The original (pre 7.10) behaviour is restored if item 229 is absent from spag.fig. - Dynamic analysis instrumentation code rewritten to deal correctly with Fortran 95 allocatable arrays, KINDs, and the use of array
sections. - Bug fixes in coverage analysis code to allow it to deal correctly with Fortran 95 modules.
- Probe routines rewritten and enhanced in Fortran 95 (in file probes.f90).
- Timing probe and report enhancements.
- SPAG copies probes.f90 to the output directory when instrumenting source for coverage analysis or dynamic analysis. probes.f90 must be compiled and linked with the instrumented code when creating executables for dynamic or coverage analysis.
- Default for SPAG configuration option 56 (location of INCLUDE files with no specified path changed to 1 (same directory as source file).
- New option for name of target executable in AUTOMAKE on Windows creates an executable with the name derived from the current working directory name.
- Manual updated to revision J. including a new section on PFFE.
plusFORT Version 7
Version 7 extends the supported language to include Fortran 95 and Fortran 2003. It also introduces greatly improved HTML static analysis reports, with comprehensive cross-reference links. These reports are designed to act as a constant companion to coders, providing instant answers to questions like “where is this variable set” and “where is this routine called from”. A new “modularization report” shows how a traditional Fortran 77 program can be reorganised using modules and/or internal subprograms to take full advantage of the modular programming features of Fortran 95 and Fortran 2003.
Try the new GXCHK report interface by clicking here. This report shows an analysis of AERMOD.f90, one of the Polyhedron benchmarks. This file has 50K lines of Fortran 90, but much larger programs (many millions of lines) can be analysed and viewed in this way. Note that most browsers allow you to right-click on links to save particular reports in a separate tab.

